Week Six: Diaries and Data

I have NEVER been good at producing original work. It’s not that I dislike what I do, I just think of too much I want to do, all at once, and with all these ideas bouncing around in my head I stagnate, unsure of where to start. The proposed work of exploratory digital history for this week caused my internal monologue to voice some concerns, but fortunately, the “reading” associated with this week hushed it. Michelle Moravec’s post shedding light on how she explored American artist Carolee Schneemann’s correspondences, step-by-step, took a bit of the guessing away from how I could approach exploring an archive using the tools we’ve been made aware of these past few weeks. The beginning of Moravec’s process seemed to be picking a topic and then making a list of tools she’d like to use to explore her subject further. At the suggestion of Dr. Graham, I immediately dove into finding a diary that seemed like it might be fun to explore. As someone who loves social history, the mundane details of life you can pull from a diary fascinate me; they can be so revealing about not only the writer, but of the world that person lives in as well. As I aimlessly scrolled through the archive, clicking on diary after diary that interested me, but was never in English, I thought to myself, “why don’t I really put digital history to the test?”
I decided that I was going to pick a diary created by a person I knew nothing about. Then, my process of exploration would be a question of how much information I could gather about them— how much of their history could I write based on what I learn from digitally exploring their diary? Ah ha! A research question! I had a goal! And from this goal came my introduction to Cecilia Beaux. The archive of her diary was made available only through the Smithsonian’s Digital Transcription Center (something that proved to be a challenge for me later…), and was only accompanied by a small amount of information about her. I had a base— Cecilia Beaux was a sought after portrait artist from the US, with her peak in fame occurring during the late 1800s and early 1900s— but I knew nothing more. Perfect.
The pages of her diary available were from the year 1912, and I was particularly drawn to her diary because I had never seen a typewritten diary before. It made me wonder what kind of person she was, using a technology typically found in professional settings for something most personal. I knew approaching a diary would be a bit different from what we’ve previously explored in this class— with it being a single entity rather than varying correspondences or a corpus composed of a collection— so I reviewed my arsenal of tools I’ve been equipped with and formed a plan built upon what I thought could be best used for text analysis.
First, I would pull the pages of her diary using wget. While her diary has been fully transcribed already, it was 1) only downloadable as an oddly formatted pdf and 2) I wanted to attempt to OCR the original scans, which was to be my second step. After I had all of the text OCR’d into one large text file, I would clean it up with regex to make it useable, then run it through my favourite exploratory tool, Voyant. After getting some “leads” through exploration with Voyant, I would play with topic modelling and see if I could relate any of my observations to the broader themes found in her life.
After this, I was ready to start! But of course, not everything went according to plan. I only wish I had a team to help edit and process my data like Moravec did— it would have made this process MUCH faster.
We-get some, we lose some
I feel like wget must be one of the most useful tools for a digital historian’s work. Rarely does the archive you want come in a neatly packed, ready-to-download format. The way that this archive of Cecilia Beaux’s diary was package was odd— each page of her diary was displayed like a gallery, and clicking through led to that page alongside its transcription, which was vetted by a group of volunteer transcribers. Useful, yes. but I wasn’t quite sure how to approach obtain the scans, or at least a link to the original image, from an archive formatted like this. First, I thought to just try pulling from the homepage of the collection. NOPE. Had to terminate that fast, wget starting downloading everything it possibly could from the website. My next approach was to just see what would happen if I tried to get the contents of an individual page of the diary. Luckily, this didn’t start pulling the whole website, but it did only get the page’s HTML and the like, rather than the original page of the diary I wanted. At this point, I decided to open the “inspect element” tool on the webpage showing an individual diary entry to look more closely at how exactly these webpages I was trying to pull from were set up. I discovered that while the Smithsonian’s Digital Transcription Center was hosting this archive, the original scans of the diary were placed in a container pulling from where they were actually hosted, within the collections of the Archive of American Art. I wasn’t able to access a gallery of these original scans, but I checked the HTML of the diary’s first three entry pages and discovered that the scans were consecutive, so I generated a quick python script to generate a text file of URLs, like we were shown to do in Week 2, then ran wget to grab files. Success! Every scan I needed was grabbed, but only after a 27min wait of course.
The process of then OCR’ing this text was simple, yet problematic. The only alterations I had to make to the code I originally wrote in Week 2 for OCR was 1) changing the folder that the images were being pulled from, and 2) I wanted my output to be in one large text file rather than numerous individual files to make cleaning and later analysis easier. When running the program with just a few of the images to make sure what I changed worked, I ran into what is apparently a flaw with the Tesseract package; I was occasionally being thrown the warning Image too small to scale!! Cannot read line!!. Google says that Tesseract can have issues with uneven lines, faded typewriting, or small fonts, which was what most of Cecilia Beaux’s diary consisted of. But according to the people of the internet, this shouldn’t cause many problems as usually it only indicates a word or two being missed, so I went ahead and OCR’d my entire collection of scans, fingers crossed.
I regretted life as soon as I opened the text file my OCR program had generated. I initially went straight to trying to isolate each entry by date, but trying to use regex to find basic written date-related terms was impossible because of the sheer amount of word fragments in the text. I opted to take a step back from cleaning and just review the file, like a responsible researcher, and oh boy. Cecilia had a penchant for using shorthand in her writing, which was occasionally indistinguishable from the word fragments created in the OCR process. Reading through the first few entries, there was undoubtedly lines missing likely caused by the Tesseract issue I had hoped would be ignorable. There was also a chunk of the file that was TOTAL gibberish. I cross-referenced this section with the original scans, only to discover that there were about 5 pages worth of entries that were handwritten, in a manner that I could barely even read, so I don’t blame Tesseract for not getting this one. This file would no doubt take me hours if not days to clean and make useable enough to get meaningful results from text analysis. If only I could just grab the transcribed text that was embedded in the HTML of the entry webpages…
Chantal Learns Web Scraping!
I decided to rebel against my original plan— I used wget and I used OCR, so I technically I followed it, but they failed me in the sense that I couldn’t make the results they produced useable in the timeframe I had to complete my work. Scraping the transcribed text would immediately give me a text file that required very few alterations to make useable. The first thing I needed to do was get the URLs for the individual entry pages, which of course did not have URLs with consecutive IDs. But I knew the homepage of the archive listed every entry in order, and from looking at the HTML of the homepage, each clickable image box contained the link to its entry’s page. I opened RStudio and use this tutorial as a starting point, but I was only able to pull the links from the first 8 entries. I quickly realized that this was because the archive’s homepage was scroll-to-load rather than paginated, and the link to the page within my code was only giving me what the webpage initially loads. My search for a solution to this gave me RSelenium, a package that would automate my web browser making it so I could fully load the entire contents of the page. I was then able to scrape the page for all of the URLs to the individual entry pages, which created… a matrix? Well, I needed the to append these URLs to the homepage’s URL to create a full address anyway, so I iterated over the matrix with a for loop, pasting the two pieces of the URL together and then adding this to a list that became a full list of URLs I could navigate to. Using this list, I looped over it, each time navigating to one entry’s page to pull the transcribed text from the page’s HTML and adding that text to a larger text file. Combined, using wget and OCR to produce the same result with a worse outcome took about an hour total. Scraping the text by going over the individual entry pages took maybe five minutes? And now, I had a workable text file.
Expressions, both Regular and in Text
Unlike my previous attempt to start cleaning my data via regex, I first looked it over. There were numerous typos, as well as text that looked fragmented or like not real words at all! I wanted to reference the original diary scans to verify information, but I realized that in the text file I was working in, there was no simple way to see which entry came from whereas Cecilia tended to write brief entries, and thus there were generally multiple entries included on every page. My solution to this was to open my code for scraping the transcriptions and add an additional variable in the loop going over the individual entry pages that would pull the original scan’s URL from HTML element it was stored in (like I did when first downloading the images with wget). I then parsed this URL to a string that only included the name of the image’s number + file type, and appended this string to the beginning of the transcribed text also found on the webpage. Running this code produced a searchable text file that I could use to verify what Cecilia wrote if I needed to. After using this to crossreference a few lines that didn’t seem right, I learned that Cecilia Beaux genuinely was an avid user of shorthand, abbreviating any frequently used word she could to a point of it just being understandable. She also seemed to abbreviate the names of the people she interacted with most. Was this because she was impatient with the technology she was using? Was she too busy to have much time to journal? Was she secretive? Looked like I’d have to explore more to find answers.
Any formatting, corrections to words the Smithsonian’s OCR missed, and notes by the transcribers were enclosed in double square brackets, making elements I didn’t want easy to remove. I decided to begin by entirely removing any words that weren’t Cecilia’s— so the formatting and transcription notes. I quickly went over the bracketed text to find common formatting terms and created an expression that would find them, then removed them. I did the same with transcription notes by finding bracketed segments with more than 2 words. Following this, I created an expression that found brackets touching a letter in order to identify the word corrections, grouping the contents in front of, within, and/or following the brackets and replacing the search with just the grouped elements. Finally, I just search for brackets to find anything I might have missed, which led to some fun discoveries. It was mostly notes written in the margins in pencil by Cecilia that were missed by my previous expressions, or struck-through text mislabelled by transcribers. These seemed to be ways Cecilia expressed her more “scandalous” thoughts, such as enamoured worry over a companion, or thoughts about rumours within her social circle. It’s odd that she felt the need to censor these things in her own diary; to me, this implies that she grew up in a society or class where expressing these sentiments would be unacceptable, and thus she felt shame upon writing them out, either crossing out the words or writing them in a way she felt was less permanent, pencilled in the margins.
At this point, the diary text seemed clean enough to analyze, although there was still some fragmented words (or rather, what I thought were fragmented words) I was worried about. Regardless, onward I went in uploading my freshly “polished” text file to Voyant Tools.
Voyant Views
Immediately upon loading Voyant’s web tool with my data, I thought my fears about fragments left in the text were correct. Cirrus showed two seemingly non-sensical “words”— “fr” and “Sl”— as one of the most frequently occurring words. I hopped back into the diary text file and did a search for both of what I presumed were errors. In actuality, “fr” revealed itself to be another one of Cecilia’s unusual abbreviations. I confirmed this with a couple of the original scans alongside the text file search, but it seemed that “fr” was used in place of “from”. For the sake of easier digital analysis, I replaced any occurrence of this abbreviation with the full word. “Sl” on the other hand, was not replaceable as it turned out to be the name of one of Cecilia’s most frequently mentioned companions— I wonder, who is Sl? I popped the updated text file on Voyant, hoping to learn more.
I first took a quick look at the “Trends” visualization and noticed that many of the words were “transient” in nature— words such as “came”, “got”, “went”— all implying some sort of travel.
I then moved on to the “Contexts” tool, not just to explore these terms further and confirm that they were in fact, expressions of travel, but also to quickly search “Sl”. Based on the context given, Sl seemed to be a rambunctious friend of Cecilia who was always inviting her to outings or parties— often either to her annoyance or pleasure. Looking at the most frequently occurring term, “came”, seemed to reveal Cecilia’s more frequently discussed acquaintances, ones who’d visit her at home or meet her elsewhere. Unsurprisingly, Sl was among these associations, but there were three others mentioned frequently, a man identified as A.P.A.— who frequently gave Cecilia books and related intellectual discussion, Jack— who seemed to be more of a gentlemanly man that Cecilia would spend quiet times with, and another simply identified as A— a joyful person and the only woman in this group. Did Cecilia tend to seek out male companionship, or was it a result of her chosen career being a public role in a field that was dominated by men?
Next, I looked at the context of “went”, which seemed to be used in Cecilia’s discussion of outings and trips she or a friend had gone on, and revealed her greater social circle. It also revealed an odd expression she used that seemed to indicate time: “Ros called up and I went in to 24 to goose.” What does “to goose” mean? She used it elsewhere in the text too, but googling it gives me no results…
“Got” seems to be the bridge between “came” and “went” in Cecilia’s diary, indicating actions such as arriving, getting ready to leave, or getting off or out of some mode of transport. I noted the large variety of transportation that seemed to be available to her— cars (personal or cabs), trains, buggies— that indicated that she likely lived in a city and that she could afford to use these modes of transport.
The final common term I investigated was “good”, which comically was used by Cecilia as her primary descriptor for both positive things, but also in an it-was-just-okay-but-I-want-to-be-polite sort of way. When genuinely pleased, Cecilia would accompany the word good with “very”, but when writing about an outing or meal hosted by friends that was less than satisfactory, it would end up being described as “pretty good” in summary. While this could simply be the way Cecilia prefers to write— after all, she’s a painter, not a writer— based on her use of shorthand, terse sentences, and her primary descriptor simply being “good”, I wonder what kind of education she received. Was she always as comfortable as she was at the time of this diary’s composition, or did she earn her status through her success in art? I referred back to the diary text, and it seems that Cecilia rarely mentioned her family, but in one occasion which she did, she also mentioned how her the servants took care of her, so I will assume the former, and that she chooses to be a very practical writer.
Besides looking at word frequency and contexts, the correlation tool kept throwing me an error so I decided to explore Cirrus.
The words featured here continued to support the image of Cecilia having a busy, on-the-go lifestyle, which isn’t totally unexpected for an in-demand artist. Some of the largest words were time specifiers and social activities, such as “called” or “talk”. There are also visible mentions of mealtimes, such as “lunch” and “din” (Cecilia’s abbreviation of dinner). When I looked at where these words were used in phrases (using, as you might have suspected, the Phrases tool), they were almost always a social occurrence, lunch or dinner being an occasion had with friends.
In analyzing with Cirrus, I also unintentionally stumbled across a few other observations about Cecilia’s life. The overall most common phrases repeated in her diary are about activities with other people, whether it be reading quietly or having a night out. Additionally, I came across a few specified locations which she was taken to or planned to go to, such as “visiting the tree” in “Mads Sq”, or going with a friend to the “Flower Market in Union Square”, leading me to believe to she was living in New York at this time, despite frequent mentions of Boston, “Phila”, and Washington.
Framing the Year
From cleaning the data and analyzing her diary through Voyant, I had a good handful of details, and questions, about Cecilia Beaux’s life in 1912. I continued with my original plan’s final step of creating topic models from her diary, because I figured it would be interesting to see the broader themes in her life. Did they align with my current interpretation of her as a busy, practical, yet “ladylike” woman, or would the topic generated offset this? Could these topics comment on the larger questions I’ve had about the society Cecilia functioned in? Before I could get answers, I had to make Cecilia’s diary that was a text file into a CSV file ready for topic modelling.
I figured I could make a CSV with three headers— entry (the entry’s number), date, and text— formatted much like the Chapbooks corpus we analyzed in Week 4. My initial thought was that I’d have to write a script to iterate over my text file to convert it into the format I wanted, but while asking my boyfriend (a computer science student) how to approach doing this, he brought up the very valid point of, “if you’re not sure about how to do this, it would probably take you the same of time or less to manually alter your text file using regex.” And he was absolutely correct— I totally overthought the task. So I duplicated my diary text file and started modifying it to match the format of a CSV. Cecilia marked her dates with relative consistency, but occasionally switched the order of the weekday and month, so I first searched for sure indicators of dates (weekday or month beside a digit) and reformatted the dates by replacing them via rearranging groups. I then added a \n~ to separate the dates and make them easily identifiable. After this, I changed the months which Cecilia, of course, abbreviated into their full name, and removed the ordinal indicators from the end of the numbered dates. I had all of the dates indicated, ready to number them for the entry column, when I realized that I had no idea how to consecutively number things using regex, and my googling skills gave me no answers. I begrudgingly accepted that I could set the column, but opening the CSV in Excel to number each entry would likely be the easiest solution to this problem. I added quotation marks around the dates alongside a comma at the end, and used this:
(["][a-zA-Z0-9~ ]+[",]+)([a-zA-Z0-9\n .,')(-_^&$]+)
monstrous expression to do the same to the text of each entry, then removed all the new lines, and shipped my CSV off to Excel. Here, it took more time for the web app to load than it took me to consecutively number the journal entries using autofill.
I pulled up the topic modelling program we created in R during Week 4, altered some variables to match my newly created CSV file, and did a speedy run through the program, just to see what the outputs would look like. The topic-value model for detecting patterns looked fine, but the proportion-time model for detecting change over time had alphabetically labelled the months instead of keeping them in order, skewing the entire purpose of the graph. I added some print lines into my code to figure out the point where my dates were being reordered, and discovered that the aggregate function automatically orders lists alphabetically. I searched for about 30mins, seeking a cure to this woe, when it dawned on me that I could just numerically represent the dates and that would probably fix the issue. I opened my CSV file in Excel and created a “months” column where I added numerical representations for each month, then went back into R and aggregated referencing that header rather than just “dates”. Success! Numbers are consecutive, thus my months were now in order!
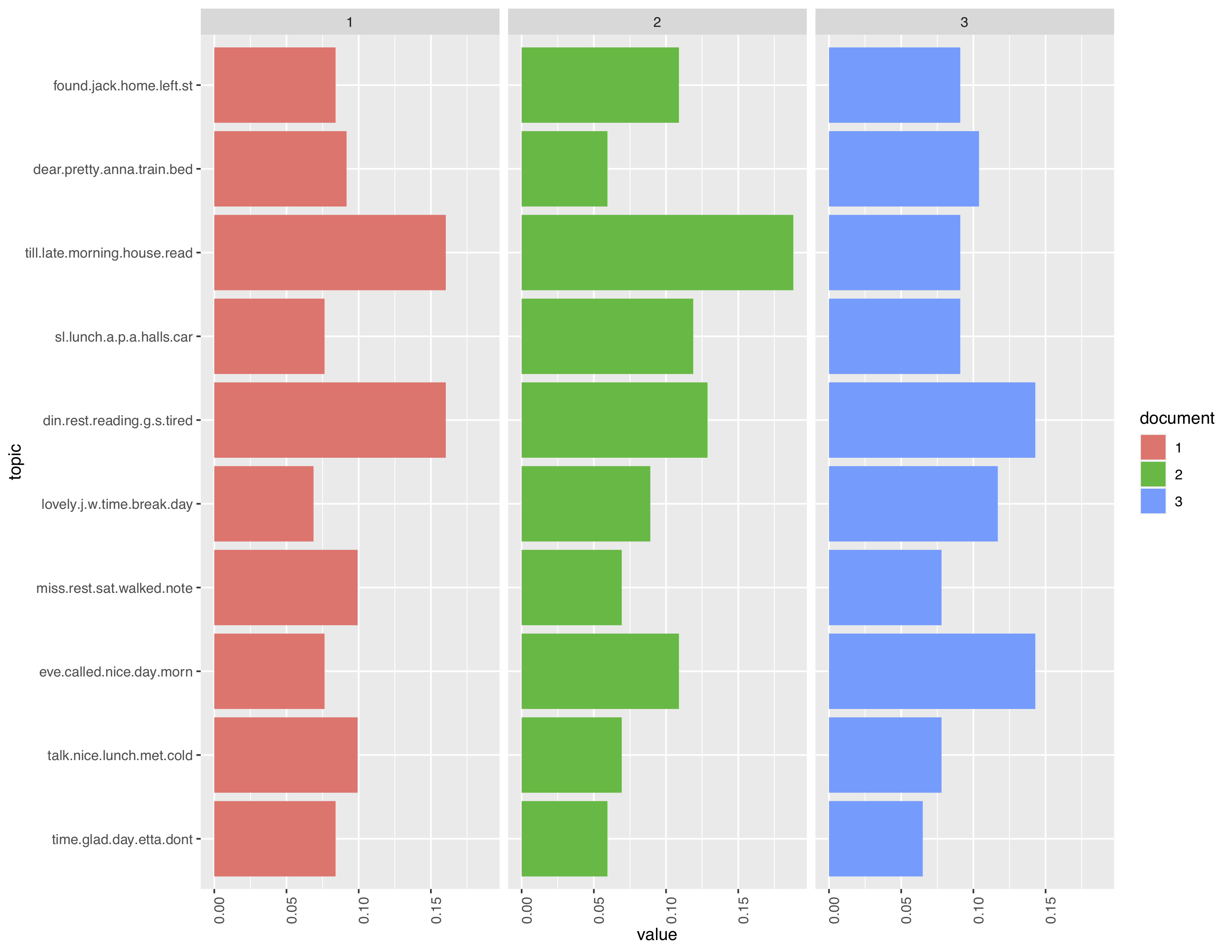
For finding patterns within topics I chose to create 10 topics, because I think this model is best for seeing a broader overview of general trends in a corpus. My imagining of Cecilia as a socialite persists, with most topics containing names or activities involving another person; but, this perception shifted when I noticed that one of the topics with a consistently higher value was “din,rest,reading,tired”. This made me question whether Cecilia was naturally this social, or if she forced herself to be in order to gain success in a time where finding it might be difficult as a female artist. Looking at other topics, there were other sprinklings of words such as “rest”, “sat”, or “bed”, indicating that she values her times of quiet enough to write in her diary about it. The topic with the consistent highest value also seemed to indicate a fondness for introversion, painting the image of a pleasant life reading and time spent at home. To dig deeper into this, I decided to move on to modelling topics over a year, this time generating 15 topics to gather more detail and view the minuet changes in Cecilia’s life across the year of 1912.
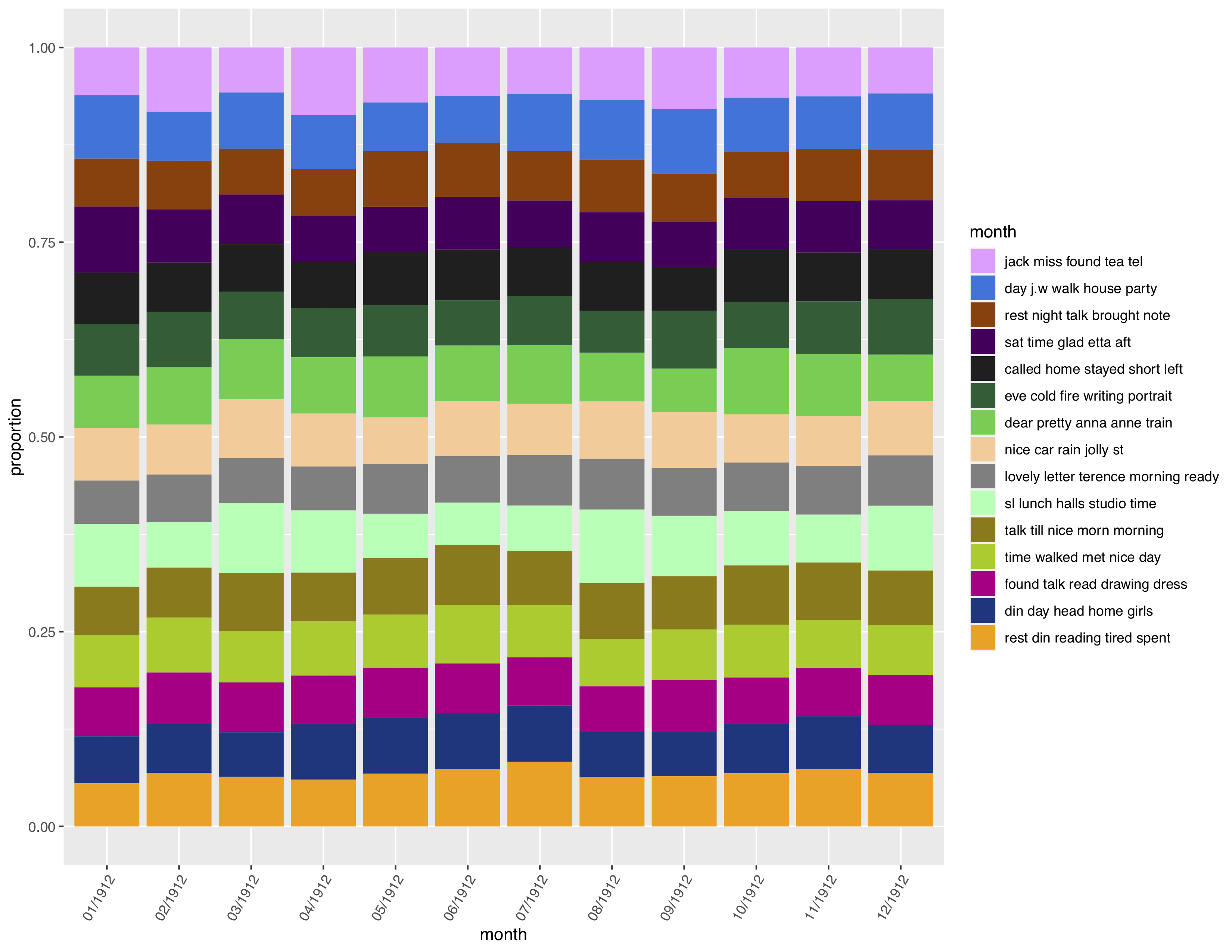
This produced a pretty evenly distributed model, but I guess that’s to be expected when you’re only modelling a year. The first thing I noticed was the overall rise in topics relating to positive language in the middle of the year aka summer months, but when looking more closely at this period of time, the topic relating to time spent in the studio took a greater proportion in August— an important commission perhaps? I checked the diary text and discovered that Cecilia was actually working on a number of portraits at this time, and having particular trouble with the “D” portrait, which would account for a increase in mentions of her work in her diary. Additionally, the general upward trend mid-year also aligns with an increase in the significance of the topic “rest din reading tired spent”. I investigated some of these terms briefly in the diary text, and noticed a common pattern of Cecilia writing about her fatigue, poor sleep and/or catching colds. While there is much more positive recollection dispersed between these entries, I wonder if Cecilia was truly able to have a balanced life, or one that was so busy that she cherished her times of rest enough to journal about it. Maybe her journalling was so to the point and abbreviated because it was something she enjoyed, but simply didn’t have much time for.
At this point, I had reached the goal I had started with. How much of a history could I write about someone I knew nothing about from digital analysis?
Cecilia Beaux, in 1912, was a 57-year-old in-demand portrait artist living in New York. She frequently travelled, most often for work, but also maintained numerous social connections throughout the US, particularly in Washington, Boston, and Philadelphia, which she dubbed “Phila” in personal writings. She came from a comfortable— likely middle class— background upholding a very polite standard of speech, even when writing in her diary. The dichotomous nature of her lifestyle found in her diary, which details a life of constant obligation contrasted by an adoration of sleep and quiet times of rest, coupled with upset over frequent colds following long journies, raises questions about what life was like for a publically successful woman in the early 1900s, and what it took to maintain that success. Cecilia Beaux’s penchant for introversion, yet extensive journaling about a bustling social life perhaps suggests the extra necessities required of a woman in a male-dominated industry to be successful. Connections must be made and maintained, and extensive travel was a must.
Exploring this archive digitally led me to form many questions— some that could be answered from exploring within the corpus, and some that I would need further time and resource to research. I could create an entire project at this point based around my discoveries in Cecilia Beaux’s diary, and how they correlated with the experiences of other prominent female artists active at the same time as she was, and this could be done once again through using digital history to exploring even more. But of course, that’s a bit too ambitious for a week so, for now, this’ll have to do.